인덱스 처리에 대해 이해하고 있다면 데이터 삽입을 위한 적절한 공간을 예약하려는 경우에 도움이 될 수 있습니다. MySQL 5.7부터 이전 릴리스에서 사용된 하향식 접근 방식이 아닌 상향식 접근 방식을 적용하여 InnoDB용 보조 인덱스를 구축하는 방식으로 변경했습니다.
인덱스 구축 프로세스
기존 데이터가 있는 테이블에 인덱스를 작성하기 위한 단계가 있습니다.
- 읽기 단계(클러스터형 인덱스에서 읽고 보조 인덱스 항목 작성)
- 병합 정렬 단계
- 삽입 단계(정렬된 레코드를 보조 색인에 삽입)
버전 5.6까지 MySQL은 한 번에 하나의 레코드를 삽입하여 보조 인덱스를 구축했습니다. 이것은 "하향식" 접근 방식입니다. 삽입 위치에 대한 검색은 루트(위쪽)에서 시작하여 적절한 리프 페이지(아래쪽)에 도달합니다. 레코드는 커서가 가리키는 리프 페이지에 삽입됩니다. 삽입 위치를 찾고 페이지 분할 및 병합(root 및 non-root에서)을 수행하는 데 비용이 많이 듭니다. 페이지 분할 및 병합이 너무 많이 발생하는지 어떻게 알 수 있습니까?
MySQL 5.7부터 인덱스 추가 중 삽입 단계는 "Bulk Load for Index"라고도 하는 "Sort Index Build"를 사용합니다. 이 접근 방식에서 인덱스는 "상향식"으로 구축됩니다. 즉, 리프 페이지(하단)가 먼저 빌드된 다음 비-리프 레벨이 루트(위)까지 빌드됩니다.
사용 사례
정렬된 인덱스 빌드는 다음과 같은 경우에 사용됩니다.
- ALTER TABLE t1 ADD INDEX (or CREATE INDEX)
- ALTER TABLE t1 ADD FULLTEXT INDEX
- ALTER TABLE t1 ADD COLUMN, ALGORITHM=INPLACE
- OPTIMIZE TABLE t1
마지막 두 사용 사례의 경우 ALTER는 중간 테이블을 생성합니다. 중간 테이블 인덱스(기본 및 보조 모두)는 "Sort Index Build"를 사용하여 빌드됩니다.
알고리즘
- 레벨 0에서 페이지를 작성하십시오. 또한 이 페이지에 대한 커서를 작성하십시오.
- 가득 찰 때까지 레벨 0의 커서를 사용하여 페이지에 삽입합니다.
- 페이지가 가득 차면 형제 페이지를 만듭니다(아직 형제 페이지에 삽입하지 마십시오).
- 현재 전체 페이지에 대한 노드 포인터(자식 페이지의 최소 키, 하위 페이지 번호)를 만들고 노드 포인터를 한 수준 위(상위 페이지)에 삽입합니다.
- 상위 레벨에서 커서가 이미 위치했는지 확인하십시오. 그렇지 않은 경우 상위 페이지와 레벨에 대한 커서를 작성하십시오.
- 상위 페이지에 노드 포인터 삽입
- 상위 페이지가 가득 차면 3, 4, 5, 6단계를 반복합니다.
- 이제 형제 페이지에 삽입하고 커서가 형제 페이지를 가리키도록 합니다.
- 모든 삽입의 끝에는 가장 오른쪽 페이지를 가리키는 각 수준에 커서가 있습니다. 모든 커서를 커밋합니다(페이지를 수정한 미니 트랜잭션을 커밋하고 모든 래치를 해제함을 의미).
단순성을 위해 위의 알고리즘은 압축된 페이지 및 BLOB(외부 저장 BLOB) 처리에 대한 세부 정보를 건너뛰었습니다.
상향식 인덱스 구축 과정
예를 사용하여 상향식 보조 인덱스가 구축되는 방식을 살펴보겠습니다. 다시 간단하게 하기 위해 리프 및 비 리프 페이지에 허용되는 최대 레코드 수가 3개라고 가정합니다.
CREATE TABLE t1 (a INT PRIMARY KEY, b INT, c BLOB);
INSERT INTO t1 VALUES (1, 11, 'hello111');
INSERT INTO t1 VALUES (2, 22, 'hello222');
INSERT INTO t1 VALUES (3, 33, 'hello333');
INSERT INTO t1 VALUES (4, 44, 'hello444');
INSERT INTO t1 VALUES (5, 55, 'hello555');
INSERT INTO t1 VALUES (6, 66, 'hello666');
INSERT INTO t1 VALUES (7, 77, 'hello777');
INSERT INTO t1 VALUES (8, 88, 'hello888');
INSERT INTO t1 VALUES (9, 99, 'hello999');
INSERT INTO t1 VALUES (10, 1010, 'hello101010');
ALTER TABLE t1 ADD INDEX k1(b);InnoDB는 기본 키 필드를 보조 인덱스에 추가합니다. 보조 인덱스 k1의 레코드는 형식 (b, a)입니다.
정렬 단계 후 레코드는 (11,1), (22,2), (33,3), (44,4), (55,5), (66,6), (77,7), (88,8), (99,9), (1010, 10)입니다.
초기 삽입 단계
레코드(11,1)부터 시작하겠습니다.
- 레벨 0(리프 레벨)에서 페이지를 작성하십시오.
- 페이지에 커서를 만듭니다.
- 모든 삽입물은 가득 찰 때까지 이 페이지로 이동합니다.

화살표는 현재 커서가 가리키는 위치를 나타냅니다. 현재 페이지 번호 5에 있으며 다음 삽입물은 이 페이지로 이동합니다.
두 개의 여유 슬롯이 더 있으므로 레코드 (22,2) 및 (33,3)을 삽입하는 것은 간단합니다.

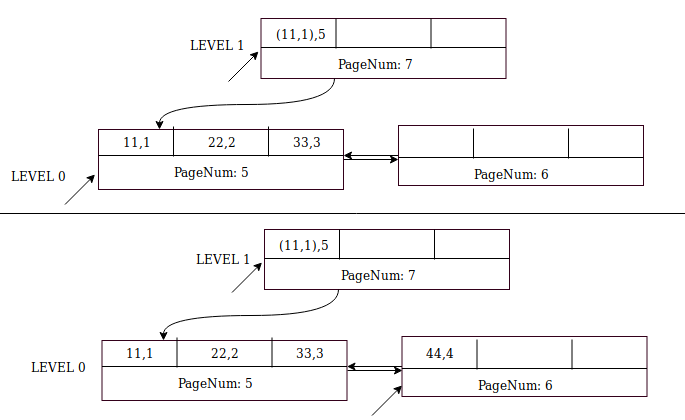
다음 레코드(44, 4)의 경우 5페이지가 꽉 찼습니다. 단계는 다음과 같습니다.
페이지가 채워지면 색인 작성
- 형제 페이지 만들기 – 6페이지
- 아직 형제 페이지에 삽입하지 마십시오.
- 커서에서 페이지 커밋, 즉 미니 트랜잭션 커밋, 래치 해제 등
- 커밋의 일부로 노드 포인터를 만들고 [현재 레벨 + 1]의 부모 페이지에 삽입합니다. 즉, 레벨 1에서
- 노드 포인터는 형식(자식 페이지의 최소 키, 하위 페이지 번호)입니다. 페이지 번호 5의 최소 키는 (11,1)입니다. 상위 수준에서 레코드((11,1),5)를 삽입합니다.
- 레벨 1의 상위 페이지는 아직 존재하지 않습니다. MySQL은 페이지 번호 7과 페이지 번호 7을 가리키는 커서를 생성합니다.
- 페이지 번호 7에 ((11,1),5) 삽입
- 이제 레벨 0으로 돌아가서 페이지 번호 5에서 6으로 또는 그 반대로 링크를 생성하십시오.
- 레벨 0의 커서는 이제 형제 페이지 번호 6을 가리킵니다.
- 페이지 번호 6에 (44,4) 삽입
(55,5) 및 (66,6)의 다음 삽입물은 간단하며 6페이지로 이동합니다.
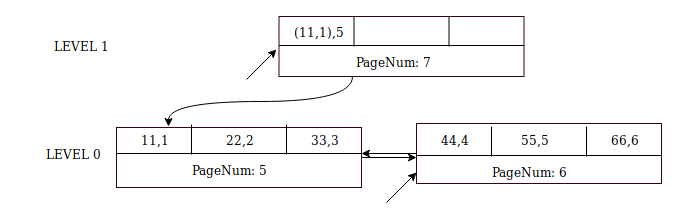
레코드 삽입(77,7)은 상위 페이지(페이지 번호 7)가 이미 존재하고 두 개 이상의 레코드를 위한 공간이 있다는 점을 제외하고는 (44,4)와 유사합니다. 노드 포인터((44,4),8)를 먼저 7페이지에 삽입한 다음 (77,7)을 형제 페이지 8에 기록합니다.
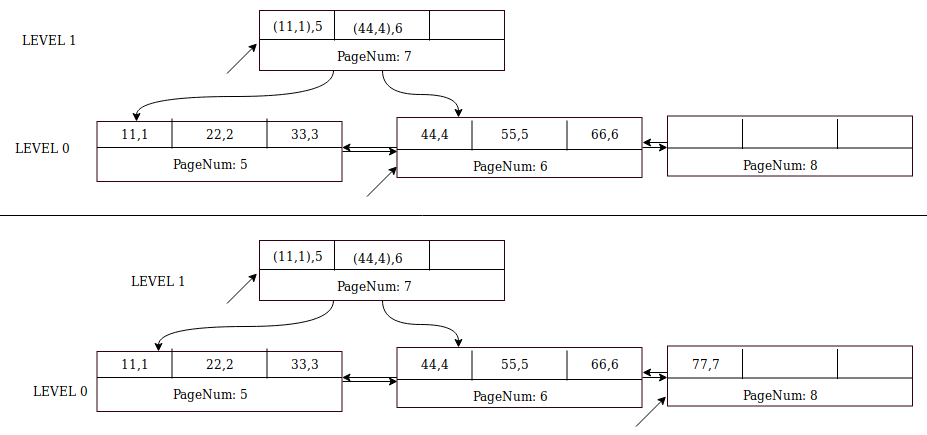
레코드 (88,8) 및 (99,9)의 삽입은 8페이지에 두 개의 여유 슬롯이 있기 때문에 간단합니다.
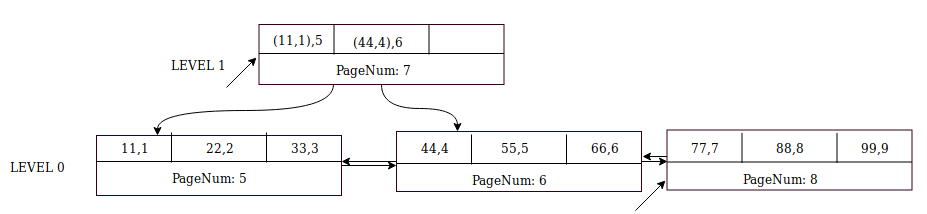
노드 포인터((77,7),8)를 수준 1의 부모 페이지(페이지 번호 7)에 삽입합니다.
MySQL은 레벨 0에서 형제 페이지 번호 9를 생성합니다. 레코드 (1010,10)을 페이지 9에 삽입하고 커서를 이 페이지로 변경합니다.

모든 수준에서 커서를 커밋합니다. 위의 예에서 데이터베이스는 레벨 0에서 페이지 9를 커밋하고 레벨 1에서 페이지 7을 커밋합니다. 이제 상향식으로 구축된 완전한 B+-트리 인덱스가 있습니다!
Index fill factor
전역 변수 " innodb_fill_factor "는 삽입에 사용할 Btree 페이지의 공간 양을 설정합니다. 기본값은 100이며 전체 페이지가 사용됨을 의미합니다(페이지 headers, trailers 제외). innodb_fill_factor = 100의 예외가 있습니다. 클러스터형 인덱스는 페이지 공간의 1/16이 여유 공간으로 유지됩니다. 즉. 6.25% 공간은 향후 DML을 위해 예약되어 있습니다.
값이 80이면 MySQL은 페이지의 80%를 삽입에 사용하고 20%는 향후 업데이트를 위해 남겨둡니다.
innodb_fill_factor가 100인 경우 보조 인덱스에 미래의 삽입을 위해 남아있는 여유 공간이 없습니다. 인덱스 추가 후 테이블에서 더 많은 DML이 예상되는 경우 페이지 분할 및 병합이 다시 발생할 수 있습니다. 이러한 경우 80-90 사이의 값을 사용하는 것이 좋습니다. 이 변수 값은 OPTIMIZE TABLE 또는 ALTER TABLE DROP COLUMN, ALGORITHM=INPLACE로 다시 생성된 인덱스에도 영향을 줍니다.
인덱스가 훨씬 더 많은 디스크 공간을 차지하기 때문에 너무 낮은 값(예: 50 미만)을 사용하면 안 됩니다. 값이 낮으면 인덱스에 더 많은 페이지가 있고 인덱스 통계 샘플링이 최적이 아닐 수 있습니다. 옵티마이저는 잘못된 통계로 비효율적인 실행 계획을 선택할 수 있습니다.
정렬된 인덱스 빌드의 장점
- 페이지 분할(압축 테이블 제외) 및 병합이 없습니다.
- 삽입 위치에 대한 반복 검색이 없습니다.
- 삽입은 redo log에 기록되지 않으므로(페이지 할당 제외) redo log 하위 시스템에 대한 부담이 적습니다.
'MySQL' 카테고리의 다른 글
| pt-kill (0) | 2021.08.19 |
|---|---|
| ONLY_FULL_GROUP_BY SQL 쿼리 실패 (0) | 2021.08.12 |
| innodb_open_files과 open_files_limit (0) | 2021.08.04 |
| pt-query-digest (0) | 2021.08.03 |
| MySQL 정적 및 동적 권한 2 (0) | 2021.07.30 |