mysqlbinlog 툴을 사용하면 binary log를 binary에서 텍스트 형식으로 변환할 수 있다. "binlog_format & binlog_rows_query_log_events "매개 변수 에 따라 다르지만 mysqlbinlog 유틸리티를 사용하여 정확한 SQL 문을 생성할 수도 있다. 하지만 mysqlbinlog 툴에는 ROLLBACK 문을 생성하는 기능이 없다. percona binlog2sql은 MySQL binary log를 디코딩하고 raw SQL을 추출하며, 플래시 백 기능을 사용하여 PITR (Point-Time Recovery)을 위한 ROLLBACK 문을 생성한다.
2. binlog2sql은 무엇인가?
binary log를 구문 분석하는 오픈 소스 도구다.
binary log에서 raw SQL 문을 추출하는 기능이 있다.
특정 시점 복구를 위해 binary log에서 ROLLBACK SQL을 생성하는 기능이 있다.
3. Mysqlbinlog vs Binlog2sql
binlog2sql 도구로 이동하기 전에 Mysqlbinlog와 bilog2sql의 출력을 비교한다. 아래 쿼리를 사용하여 binlog 이벤트를 생성한다.
앞에서 언급했듯이이 binlog2sql 도구는 INSERT, DELETE, UPDATE에 대해서만 롤백을 지원한다. DDL 문은 binary log에 실제 데이터를 기록하지 않으므로 DDL을 지원하지 않는다. binlog2sql은 암호화, 압축 binary log에서 작동하지 않는다. binlog2sql은 MySQL 5.6 및 MySQL 5.7 환경에서 테스트되었다.
================================================================================================================================================================ Package Arch Version Repository Size ================================================================================================================================================================ Installing: sysbench x86_64 1.0.17-2.el7 EPEL7 152 k Installing for dependencies: ck x86_64 0.5.2-2.el7 EPEL7 26 k luajit x86_64 2.0.4-3.el7 EPEL7 343 k
Threads fairness: events (avg/stddev): 5778.7091/210.35 execution time (avg/stddev): 239.9658/0.03
본 테스트 시스템에서는 threads가 130이 넘으면 에러가 발생하고, table_size가 1000000000000 이상이면 동작하지 않으므로 적절한 값으로 조절하여 수행 하면 된다.
다음 테스트는 time 240으로 table_size 와 threads에 변화에 따른 tps 수치 변화를 표로 만들어 보았다.
threads=50
threads=120
table_size=1000000
transactions: 466736 (1944.34 per sec.) queries: 9358012 (38983.83 per sec.)
transactions: 402868 (1677.81 per sec.) queries: 8057378 (33556.21 per sec.)
table_size=10000000000
transactions: 639694 (2664.91 per sec.) queries: 12793880 (53298.20 per sec.)
transactions: 614487 (2559.47 per sec.) queries: 12289812 (51189.78 per sec.)
threads 값 보다는 table_size가 tps에 더 많은 영향을 미치고 오히려 threads가 높으면 Latency가 높아서 성능이 더 떨어지는 상황이 발생 하였다.
테스트시 수행되는 SQL의 패턴은 다음과 같다.
BEGIN; SELECT c FROM sbtest WHERE id=N; SELECT c FROM sbtest WHERE id BETWEEN N AND M; SELECT SUM(K) FROM sbtest WHERE id BETWEEN N and M; SELECT c FROM sbtest WHERE id between N and M ORDER BY c; SELECT DISTINCT c FROM sbtest WHERE id BETWEEN N and M ORDER BY c; UPDATE sbtest SET k=k+1 WHERE id=N; UPDATE sbtest SET c=N WHERE id=M; DELETE FROM sbtest WHERE id=N; INSERT INTO sbtest VALUES (...); COMMIT;
> create user test@'localhost'; > grant all privileges on *.* to test@'localhost';
> create user test2@'%' identified by 'test2'; > grant all privileges on *.* to test2@'%'; > create user test2@'localhost' identified by 'test2'; > grant all privileges on *.* to test2@'localhost';
위와 같이 에러가 발생하는데 스크립트 상에 오류와 데이터에 문제가 좀 있어 수정이 필요하다.
mysql_load_db.sh 파일을 열어 다음 부분을 찾아 수정한다.
변경 전
command_exec "$MYSQL $DB_NAME -e \"LOAD DATA $LOCAL INFILE \\\"$DB_PATH/$FN.data\\\" \ INTO TABLE $TABLE FIELDS TERMINATED BY '\t' ${COLUMN_NAMES} \""
젼경 후
command_exec "$MYSQL $DB_NAME -e \"LOAD DATA LOCAL INFILE \\\"$DB_PATH/$FN.data\\\" \ INTO TABLE $TABLE character set latin1 FIELDS TERMINATED BY '\t' ${COLUMN_NAMES} \""
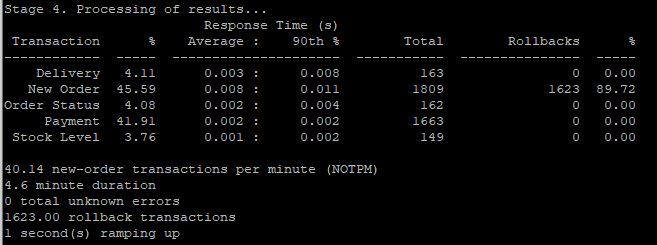
옵티마이저의판단을알기위한방법으로 explain 명령어를사용한다. 하지만 explain은옵티마이저가최종적으로선택한실행계획뿐이고, 그과정에최적화나비용계산, 또는실행계획의비교가어떻게일어났는지는알수없다. 옵티마이저트레이스에는이러한내용이설명되어있다.
mysql> explain select * from t1 join t3 on (t1.c1=t3.pk and t3.pk < 113); +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------------------+ | 1 | SIMPLE | t3 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2 | 100.00 | Using where | | 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10 | 10.00 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------------------+ 2 rows in set, 1 warning (0.00 sec)
옵티마이저트레이스의사용법은간단하다.
옵티마이저트레이스를활성화한다.
해석하고싶은쿼리를실행한다.
트레이스를출력한다.
SQL을 수행하면 아래 그림처럼 진행이 되는데, 옵티마이저 트레이스를 출력하면 옵티마이저가 하는 역할을 그대로 확인 할 수 있다.
실행계획은 information_schema에서 json 형식으로볼수있다.
select * from inforamtion_schema.optimizer_trace\G;
옵티마이저 트레이스를 제어하는 시스템 변수를 확인 하자.
세션 변수이므로 그냥 변경하면 현재 세션에만 적용 된다.
- 옵티마이저트레이스의활성화/ 비활성화
set optimizer_trace='enabled=on'; set optimizer_trace='enabled=off';
- 옵티마이저 트레이스 최대 저장 갯수 변경
SET optimizer_trace_offset=-2, optimizer_trace_limit=5; << 마지막 2개 수생된거 부터 5개 저장 SET optimizer_trace_offset=0, optimizer_trace_limit=5; << 마지막 수행된거 부터 5개 저장 (추천, limit 값만 조절 할 것)
※ 최대 출력 갯수는 optimizer_trace_max_mem_size 의 영향을 받는다.
- 옵티마이저 트레이스 다중 출력
select * from information_schema.optimizer_trace ; << 순서대로 모두 출럭 (추천) select * from information_schema.optimizer_trace limit 1 ; << 1번째 1개 출력 select * from information_schema.optimizer_trace limit 1 offset 1 ; << 2번째 1개 출력 select * from information_schema.optimizer_trace limit 2 offset 0 ; << 1번째 부터 2개 출력 select * from information_schema.optimizer_trace limit 2 offset 1 ; << 2번째 부터 2개 출력 select * from information_schema.optimizer_trace limit 2 offset 2 ; << 3번째 부터 2개 출럭
쿼리를수행하고트레이스를확인해보았다.
출력되는 결과가 너무 길어서 잘라서 보자.
mysql> select * from information_schema.optimizer_trace\G; *************************** 1. row *************************** QUERY: select * from t1 join t3 on (t1.c1=t3.pk and t3.pk < 113) TRACE: { "steps": [ { "join_preparation": { "select#": 1, "steps": [ { "expanded_query": "/* select#1 */ select `t1`.`c1` AS `c1`,`t1`.`c2` AS `c2`,`t3`.`pk` AS `pk`,`t3`.`i` AS `i` from (`t1` join `t3` on(((`t1`.`c1` = `t3`.`pk`) and (`t3`.`pk` < 113))))" }, { "transformations_to_nested_joins": { "transformations": [ "JOIN_condition_to_WHERE", "parenthesis_removal" ], "expanded_query": "/* select#1 */ select `t1`.`c1` AS `c1`,`t1`.`c2` AS `c2`,`t3`.`pk` AS `pk`,`t3`.`i` AS `i` from `t1` join `t3` where ((`t1`.`c1` = `t3`.`pk`) and (`t3`.`pk` < 113))" } } ] } },
QUERY 컬럼을통해실제입력된쿼리를알수있다.
join_preparation의select#은 explain의 id와동일한값이다.
join_preparation의transformations_to_nested_joins에서쿼리의실행계획을찾기전에쿼리를완전한형태로열어조인문의 on 절에있는조건을 where 절로이동시킨다.