용어사전 :
chunk : 데이터가 저장되는 단위
tombstone : chunk 파일에서 데이터를 즉시 삭제하는 대신 삭제를 기록
WAL : 서버 재 시작이나 crash로 부터 보호를 위한 log
symbol : 시리즈의 레이블 쌍에서 발생한 중복 제거 된 문자열
1. Index Disk Format
다음 각 블록 디렉토리에 있는 index 파일의 형식을 설명합니다
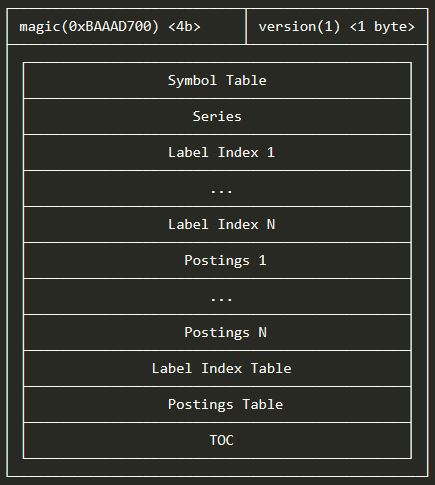
인덱스가 작성 될 때, 위의 줄이 그어진 메인 섹션 사이에 임의의 수의 패딩 바이트가 추가 될 수 있습니다. 파일을 순차적으로 스캔 할 때 섹션의 지정된 길이 뒤에 오는 0 바이트는 건너 뛰어야합니다.
아래에 설명 된 대부분의 섹션은 len필드로 시작 합니다. 항상 후행 CRC32 체크섬 바로 앞의 바이트 수를 지정합니다. 체크섬은 항상 해당 len바이트에 대해 계산 됩니다.
1.1. Symbol Table
Symbol 테이블은 저장된 시리즈의 레이블 쌍에서 발생한 중복 제거 된 문자열의 정렬 된 목록을 보유합니다. 후속 섹션에서 참조 할 수 있으며 총 인덱스 크기를 크게 줄일 수 있습니다.
이 섹션에는 문자열 항목의 시퀀스가 포함되며 각 항목에는 원시 바이트의 문자열 길이가 접두사로 붙습니다. 모든 문자열은 utf-8로 인코딩됩니다. 문자열은 순차 인덱싱으로 참조됩니다. 문자열은 사전 순으로 오름차순으로 정렬됩니다.

1.2. Series
이 섹션에는 시리즈의 레이블 세트와 블록 내의 청크가 포함 된 시리즈의 시퀀스가 포함됩니다. 시리즈는 레이블 세트를 기준으로 사전 순으로 정렬됩니다.
각 시리즈 섹션은 16 바이트로 정렬됩니다. 시리즈의 ID는 offset/16 정의됩니다. 시리즈의 ID는 다른 곳에 참조되어 사용됩니다. 따라서 정렬 된 시리즈 ID 목록은 사전 순으로 정렬 된 시리즈 레이블 세트 목록을 의미합니다.

모든 시리즈 항목은 먼저 레이블 수를 보유하고 레이블 이름과 값을 포함하는 기호 테이블 참조의 튜플이 뒤 따릅니다. 레이블 쌍은 사전 순으로 정렬됩니다.
레이블 뒤에는 인덱싱 된 청크 수가 인코딩되고 그 뒤에 청크 최소 ( mint) 및 최대 ( maxt) 타임 스탬프와 chunk 파일에서의 해당 위치에 대한 참조가 포함 된 메타 데이터 항목 시퀀스가 이어집니다. mint는 첫 번째 샘플의 시간과 maxt는 chunk의 마지막 샘플의 시간입니다. 인덱스에 시간 범위 데이터를 보유하면 쿼리 된 시간 범위와 관련이 없는 chunk를 직접 액세스하지 않고도 삭제할 수 있습니다.
첫 chunk의 mint 저장되고, 델타로 maxt 저장되고, 후속 chunk 대해 이전 시간에 대한 델타로 mint와 maxt는 인코딩된다. 유사하게, 첫 번째 청크의 참조가 저장되고 다음 참조는 이전 참조에 대한 델타로 저장됩니다.

1.3. Label Index
레이블 인덱스 섹션은 하나 이상의 레이블 이름에 대한 기존 (결합 된) 값을 인덱싱합니다. #names 필드는 색인화 된 라벨 이름의 수를 결정하고,그 뒤에 #entries 필드의 총 항목 수가 표시됩니다. 본문은 기호 테이블 참조의 #entries / #names 튜플을 보유하며, 각 튜플은 #names 길이입니다. value 튜플은 사전 순으로 오름차순으로 정렬됩니다. 이는 더 이상 사용되지 않습니다.
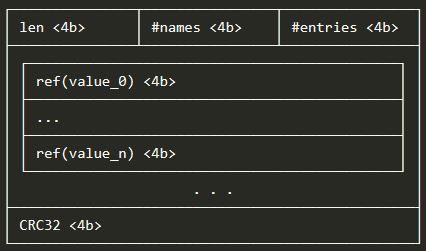
예를 들어, 4 개의 다른 값을 가진 단일 라벨 이름은 다음과 같이 인코딩됩니다.

레이블 인덱스 섹션의 순서는 주어진 레이블 이름에 대한 각 레이블 인덱스 섹션의 시작을 가리키는 레이블 오프셋 항목을 포함 하는 레이블 오프셋 테이블에 의해 마무리됩니다 .
1.4. Postings
게시 섹션은 목록과 연관된 지정된 레이블 쌍을 포함하는 시리즈 참조의 단조 증가 목록을 저장합니다.

게시 섹션의 순서 는 지정된 레이블 쌍에 대한 각 게시 섹션의 시작을 가리키는 게시 오프셋 항목을 포함 하는 게시 오프셋 테이블에 의해 마무리됩니다 .
1.5. Label Offset Table
레이블 오프셋 테이블은 일련의 레이블 오프셋 항목을 저장합니다. 모든 레이블 오프셋 항목에는 레이블 색인 섹션의 값에 대한 레이블 이름과 오프셋이 있습니다. 레이블 인덱스 섹션을 추적하는 데 사용됩니다. 이것은 더 이상 사용되지 않습니다.

1.6. Postings Offset Table
posting 오프셋 테이블은 라벨 이름과 값별로 정렬 된 일련의 posting 오프셋 항목을 저장합니다. 모든 posting 오프셋 항목에는 레이블 이름 / 값 쌍과 posting 섹션의 시리즈 목록에 대한 오프셋이 있습니다. posting 섹션을 추적하는 데 사용됩니다. 인덱스 파일이 로드 될 때 부분적으로 메모리로 읽혀집니다.

1.7. TOC
전체 색인에 대한 진입 점 역할을하며 파일의 다양한 섹션을 가리 킵니다. 참조가 0이면 해당 섹션이 존재하지 않으며 조회시 빈 결과가 반환되어야 함을 나타냅니다.

2. Chunks Disk Format
chunks/ 디렉토리에 생성되는 chunk 파일의 형식을 설명합니다. 세그먼트 파일 당 최대 크기는 512MiB입니다.
파일의 chunk는 in-file offset(lower 4 bytes) 및 세그먼트 시퀀스 번호 (upper 4 bytes)로 구성된 uint64에 의해 인덱스에서 참조됩니다.

Chunk

3. Head Chunks on Disk Format
chunks_head/ 데이터 디렉터리 내의 디렉터리에 생성되는 chunk 파일의 형식을 설명합니다 .
파일의 chunk는 in-file offset(lower 4 bytes) 및 세그먼트 시퀀스 번호 (upper 4 bytes)로 구성된 uint64에 의해 인덱스에서 참조됩니다.

Chunk
온 디스크 블록의 chunk와 달리 여기에 chunk가 속한 시리즈 참조와 chunk의 최소/최대 값을 추가로 저장합니다. 이는 chunk와 관련된 인덱스가 없기 때문에 chunk를 재생하는 동안 이러한 메타 정보가 사용됩니다.

4. Tombstones Disk Format
다음은 블록의 최상위 디렉토리에있는 tombstones 파일의 형식을 설명합니다.
마지막 8 바이트는 Stones 섹션의 시작 오프셋을 지정합니다. 스톤 섹션은 빠른 스캔을 위해 4의 배수로 0을 붙입게 됩니다.

Tombstone

5. WAL Disk Format
미리 쓰기 로그는 번호가 매겨지고 순차적 인 세그먼트에서 작동합니다. 예를 들면 000000, 000001, 000002등, 그리고 기본적으로 128MB 제한된다. 세그먼트는 32KB 페이지에 기록됩니다. 가장 최근 세그먼트의 마지막 페이지만 부분적 일 수 있습니다. WAL 레코드는 현재 페이지의 나머지 공간을 초과 할 경우 하위 레코드로 분할되는 불투명 한 바이트 조각입니다. 레코드는 세그먼트 경계로 분할되지 않습니다. 단일 레코드가 기본 세그먼트 크기를 초과하면 더 큰 크기의 세그먼트가 생성됩니다. 페이지 인코딩은 LevelDB's/RocksDB's write ahead log에서 차용됩니다 .
레코드 조각이 다음과 같이 인코딩됩니다.

플래그의 상태는 다음과 같습니다.
0: 페이지는 비어 있습니다.
1: 단일 조각으로 인코딩 된 전체 레코드
2: 레코드의 첫 번째 조각
3: 레코드의 중간 부분
4: 레코드의 마지막 조각
5.1. Series records
시리즈 레코드는 시리즈와 고유 ID를 식별하는 레이블을 인코딩합니다.

5.2. Sample records
샘플 레코드는 샘플을 트리플 목록으로 인코딩합니다 (series_id, timestamp, value). 시리즈 참조 및 타임 스탬프는 첫 번째 샘플의 델타로 인코딩됩니다. 첫 번째 행에는 시작 ID와 시작 타임 스탬프가 저장됩니다. 첫 번째 샘플 레코드는 두 번째 행에서 시작됩니다.

5.3. Tombstone records
tombstone 레코드는 삭제 표시를 트리플 목록으로 인코딩 (series_id, min_time, max_time) 하고 시리즈 샘플이 삭제되는 간격을 지정합니다.

'ETC DB' 카테고리의 다른 글
| prometheus Alert Manager (0) | 2021.07.22 |
|---|---|
| prometheus 실행 (0) | 2021.07.22 |
| prometheus TSDB 관리 API (0) | 2021.07.21 |
| prometheus disk storage (0) | 2021.07.21 |
| prometheus 데이터 구조 (2) | 2021.07.21 |