1. 로컬 저장소 (디스크 레이아웃)
Prometheus의 로컬 데이터베이스는 시계열 데이터를 디스크에 사용자 지정 형식으로 저장합니다.
수집 된 샘플은 2시간 단위로 그룹화 됩니다. 각 그룹은 해당 기간에 대한 모든 시계열 샘플을 포함하는 하나 이상의 chunk 파일과 메타 데이터 파일 및 측정 항목 이름과 레이블을 chunk 파일의 시계열로 인덱싱 한 인덱스 파일을 포함하는 디렉토리로 구성됩니다. API를 통해 시리즈를 삭제하면 chunk 파일에서 데이터를 즉시 삭제하는 대신 삭제 기록이 별도의 tombstone 파일에 저장됩니다.
현재 수신되는 샘플은 메모리에 보관 되며 완전히 유지되지 않습니다. WAL(write-ahead-log)에 의해 서버 재 시작이나 crash로 부터 보호됩니다. write-ahead log 파일은 128MB 세그먼트로 WAL 디렉토리에 저장 됩니다. 이러한 파일에는 아직 압축되지 않은 raw 데이터가 포함되어 있으므로 일반 블록 파일보다 훨씬 큽니다. Prometheus는 최소 3개의 write-ahead log 파일을 보관하지만 트래픽이 많은 서버는 최소 2시간 분량의 raw 데이터를 보관해야 하므로 3개 이상의 WAL 파일을 볼 수 있습니다.
Prometheus 서버 데이터 디렉토리 구조는 다음과 같습니다.
./data
├── 01BKGV7JBM69T2G1BGBGM6KB12
│ └── meta.json
├── 01BKGTZQ1SYQJTR4PB43C8PD98
│ ├── chunks
│ │ └── 000001
│ ├── tombstones
│ ├── index
│ └── meta.json
├── 01BKGTZQ1HHWHV8FBJXW1Y3W0K
│ └── meta.json
├── 01BKGV7JC0RY8A6MACW02A2PJD → 블록 chunk
│ ├── chunks → chunk 파일
│ │ └── 000001
│ ├── tombstones → 삭제 여부 표시 파일
│ ├── index → 색인을 위한 라벨 및 시간 인덱스 파일
│ └── meta.json → 블록의 메타 데이터
├── chunks_head → chunk head
│ └── 000001
└── wal
├── 00000002 → wal 파일
└── checkpoint.00000001 → crash 복구를 위한 checkpoint wal 파일
└── 00000000로컬 스토리지의 한계는 클러스터 되거나 복제 되지 않는다는 것입니다. 따라서 디스크 또는 노드 중단시 임의로 확장 가능하거나 내구성이 없으며 다른 종류의 단일 노드 데이터베이스 처럼 취급해야 합니다. 내구성 향상을 위해 디스크 가용성, 백업용 스냅 샷 , RAID를 사용하는 것이 좋습니다. 적절한 스토리지 내구성과 계획을 통해 로컬 스토리지에 수년간의 데이터를 저장할 수 있습니다.
또는 원격 읽기 / 쓰기 API 를 통해 외부 저장소를 사용할 수 있습니다 . 이러한 시스템은 내구성, 성능 및 효율성이 크게 다르기 때문에 신중한 평가가 필요합니다.
2. 압축
[root@prometheus-main data]# ls -al
합계 4
drwxr-xr-x 26 root root 4096 9월 3 14:40 .
drwxrwxr-x 5 deploy deploy 186 9월 3 14:33 ..
drwxr-xr-x 3 root root 68 8월 20 00:00 01EG3KQX64RZXVTQFRH28A8WHW
drwxr-xr-x 3 root root 68 8월 20 18:00 01EG5HHEDYS67X2YA772V0SXQQ
drwxr-xr-x 3 root root 68 8월 21 12:00 01EG7FAZPEP7S9HQJ94QCQ2Z99
drwxr-xr-x 3 root root 68 8월 22 06:00 01EG9D4GXQT5WR9YNFFHXY0F3Y
drwxr-xr-x 3 root root 68 8월 23 00:00 01EGBAY25F583CCKZGF2Q520XA
drwxr-xr-x 3 root root 68 8월 23 18:00 01EGD8QKEM6GSPM3KPKYTA11RS
drwxr-xr-x 3 root root 68 8월 24 12:00 01EGF6H4NRDRRAA3A2RJJC3DH3
drwxr-xr-x 3 root root 68 8월 25 06:00 01EGH4ANXSE2RQWE6N83SF0M7R
drwxr-xr-x 3 root root 68 8월 26 00:00 01EGK24764FT94BRPBW7P3M7XD
drwxr-xr-x 3 root root 68 8월 26 18:00 01EGMZXRE7SDZMVF86KBW9K8H3
drwxr-xr-x 3 root root 68 8월 27 12:00 01EGPXQ9P549DKMTVJDDFAY8QS
drwxr-xr-x 3 root root 68 8월 28 06:00 01EGRVGTYSXTNY6YK3VN41PV8W
drwxr-xr-x 3 root root 68 8월 29 00:00 01EGTSAC680AFKS7BQNZVSPF7D
drwxr-xr-x 3 root root 68 8월 29 18:00 01EGWQ3XE4WHM6M57E9T3YXF53
drwxr-xr-x 3 root root 68 8월 30 12:00 01EGYMXENNJ8DENS500B54TPNV
drwxr-xr-x 3 root root 68 8월 31 06:00 01EH0JPZXTQW0F1WM2RGGJ12SF
drwxr-xr-x 3 root root 68 9월 1 00:00 01EH2GGH60VC48XBBTF3VV1RM8
drwxr-xr-x 3 root root 68 9월 1 18:00 01EH4EA2E2106ER8YM38Q01BEN
drwxr-xr-x 3 root root 68 9월 2 12:00 01EH6C3KNMSFGBGFPQ47CF7309
drwxr-xr-x 3 root root 68 9월 3 06:00 01EH89X4XNW47X8BTZHFNG40QQ
drwxr-xr-x 3 root root 68 9월 3 12:00 01EH8YGAHX9ZTXZ627YF9AP5F7
drwxr-xr-x 3 root root 68 9월 3 12:00 01EH8YGAMHPGSBCZMF9P79F06M
drwxr-xr-x 3 root root 68 9월 3 14:00 01EH95C1T9EA9PVHD8J886VT7P
drwxr-xr-x 2 root root 62 9월 3 14:33 walchunk 블록은 백그라운드에서 더 긴 시간의 블록으로 병합 됩니다.
블록은 시간이 흐른다고 계속해서 늘어나지 않습니다. 프로메테우스의 옵션을 어떻게 설정했느냐에 따라 블록이 계속해서 합쳐질 수도 있고, retention에 따라서 삭제될 수도 있습니다. 이에 관련된 옵션은 아래 두 가지가 있습니다.
--storage.tsdb.min-block-duration : 하나의 블록에 저장될 데이터의 time을 뜻합니다. 예를 들어 이 옵션의 값이 2h일 경우, 하나의 chunk 블록 디렉터리에는 2시간 동안의 데이터가 들어가 있습니다.
--storage.tsdb.max-block-duration : 하나의 블록에 최대로 저장할 수 있는 time을 뜻합니다. 예를 들어 이 옵션의 값이 12h일 경우, 하나의 chunk 블록 디렉터리에서는 최대 12시간 만큼의 데이터를 보관할 수 있습니다. 기본 값은 블록의 retention을 설정하는 옵션인 --storage.tsdb.retention.time의 10%로 설정됩니다. 위 예제에서는 18시간 블록으로 병합 되었습니다.

위 그림에서는 min-block-duration이 2h이기 때문에 2시간 단위의 Level 1 블록이 저장되어 있습니다. 이 때, 3개의 블록이 모이는 순간 Level 2의 블록으로 합쳐지게 되며, 하나의 블록에서 6시간의 데이터를 저장하게 됩니다. 한 번에 합쳐지는 블록의 갯수는 3으로 고정되어 있으며, 병합되는 블록의 Time은 exponential하게 증가하도록 되어 있습니다. 쉽게 설명하자면, 위 예시에서는 2h * 3 = 6h의 블록이 하나 생성되고 나서 더 이상의 병합은 발생할 수 없지만, max-block-duration이 24h라면 6h * 3 = 18h에 해당하는 블록도 새로 생성될 수 있습니다.
해당 블록의 정보는 meta.json에서도 확인 할 수 있습니다. 아래의 예시는 9개의 블록이 1개의 새로운 블록으로 병합된 경우(level 3)의 meta.json 파일 내용을 보여주고 있습니다. minTime/maxTime이 블록의 Time에 해당하는 값인데, 이 값들은 부모 블록의 값을 물려 받았음을 알 수 있습니다.
[root@prometheus-main 01EH0JPZXTQW0F1WM2RGGJ12SF]# cat meta.json
{
"ulid": "01EH0JPZXTQW0F1WM2RGGJ12SF",
"minTime": 1598745600000,
"maxTime": 1598810400000,
"stats": {
"numSamples": 4808160,
"numSeries": 742,
"numChunks": 40068
},
"compaction": {
"level": 3,
"sources": [
"01EGYMXEHY3P9EDQSQSQY70ESR",
"01EGYVS5SY8S0W83GTR861JQ3N",
"01EGZ2MX1XTAMBXXKF5Y2DJ1TY",
"01EGZ9GM9Y3JBAYHV03XX6RFDZ",
"01EGZGCBHYXDM7K4YW2M2YZYXM",
"01EGZQ82SYM96D0EPKNFFHSJ1E",
"01EGZY3T1YX7R46X94H1VXZJMR",
"01EH04ZH9Y1A1QFX3AM2YT1W4W",
"01EH0BV8HXEZP0HRM85D30BFGD"
]
},
"version": 1
}
3. 로컬 저장소 설정
Prometheus에는 로컬 저장소를 구성 할 수있는 여러 플래그가 있습니다.
--storage.tsdb.path: Prometheus가 데이터베이스를 작성하는 위치를 결정합니다. 기본값은 data/.
--storage.tsdb.retention: 이 플래그 대신 storage.tsdb.retention.time 사용
--storage.tsdb.retention.time: 오래된 데이터를 제거 할 시기를 결정합니다. 기본값은 15d. storage.tsdb.retention 플래그가 기본값이 아닌 다른 것으로 설정된 경우 현재 설정으로 재정의 합니다.
--storage.tsdb.retention.size: 스토리지 블록이 사용할 수 있는 최대 바이트 수를 결정합니다 (WAL 크기는 포함되지 않음). 가장 오래된 데이터가 먼저 제거됩니다. 기본값은 0또는 비활성화입니다. 이 플래그는 실험적이어서 향후 릴리즈에서 변경 될 수 있습니다. 지원되는 단위 : B, KB, MB, GB, TB, PB, EB. 예 : "512MB"
--storage.tsdb.wal-compression: 이 플래그를 사용하면 미리 쓰기 로그 (WAL)를 압축 할 수 있습니다. 데이터에 따라 약간의 추가 CPU 부하로 WAL 크기가 절반으로 줄어들 것으로 예상 할 수 있습니다. 이 플래그는 2.11.0에서 도입 되었으며 2.20.0에서 기본으로 활성화되었습니다. Prometheus를 2.11.0 이하 버전으로 downgrade하려면 WAL을 삭제해야합니다.
시간 및 크기 보존 정책이 모두 지정된 경우 먼저 트리거되는 정책이 사용됩니다.
만료 된 블록 정리는 백그라운드 일정에 따라 발생합니다. 만료 된 블록을 제거하는 데 최대 2 시간이 걸릴 수 있습니다. 만료 된 블록은 정리하기 전에 완전히 만료되어야합니다.
평균적으로 Prometheus는 샘플 당 약 1-2 바이트 만 사용합니다. 따라서 Prometheus 서버의 용량을 계획하려면 대략적으로 아래 공식을 사용할 수 있습니다.
needed_disk_space = retention_time_seconds * ingested_samples_per_second * bytes_per_sample초당 수집 된 샘플의 속도를 조정하려면 스크랩하는 시계열 수를 줄이거나 (타겟 당 더 적은 smaple 수 또는 더 적은 수의 타겟) 스크래핑 간격을 늘릴 수 있습니다. 그러나 시리즈 내의 sample 압축으로 인해 시리즈 수를 줄이는 것이 더 효과적 일 수 있습니다.
로컬 저장소가 손상되면 가장 좋은 방법은 Prometheus를 종료하고 전체 저장소 디렉터리를 제거하는 것입니다. 개별 블록 디렉터리 또는 WAL 디렉터리를 제거하여 문제를 해결할 수 있습니다. 즉, 블록 디렉터리 당 약 2시간 분량의 데이터 sample을 잃게됩니다. 다시 말하지만, Prometheus의 로컬 스토리지는 내구성있는 스토리지가 아닙니다.
주의 : Non-POSIX 호환 파일 시스템은 복구 불가능한 손상이 발생할 수 있으므로 Prometheus의 로컬 스토리지에서 지원되지 않습니다. NFS 파일 시스템 (AWS의 EFS 포함)은 지원되지 않습니다. NFS는 POSIX와 호환 될 수 있지만 완전하지 않기 때문에 안정성을 위해 로컬 파일 시스템을 사용하는 것이 좋습니다.
4. remote 스토리지
Prometheus의 로컬 스토리지는 확장성과 내구성 측면에서 단일 노드로 제한됩니다. Prometheus 자체에서 클러스터 된 스토리지를 사용하는 대신 Prometheus는 원격 스토리지 시스템과 통합 할 수있는 인터페이스 세트를 가지고 있습니다.
Prometheus는 다음 두 가지 방식으로 원격 스토리지 시스템과 통합됩니다.
- Prometheus는 표준화 된 형식으로 원격 URL에 수집하는 샘플을 작성할 수 있습니다.
- Prometheus는 표준화 된 형식으로 원격 URL에서 샘플 데이터를 읽을 수 있습니다.

읽기 및 쓰기 프로토콜은 모두 HTTP를 통한 snappy-compressed 프로토콜 버퍼 인코딩을 사용합니다. 프로토콜은 아직 안정적인 API로 간주되지 않아서 향후 Prometheus와 원격 저장소 간의 모든 통신이 HTTP/2를 지원 할 수 있을 때 HTTP/2를 통해 gRPC(구글이 최초로 개발한 오픈 소스 원격 프로시저 호출)를 사용하도록 변경 될 수 있습니다.
읽기 경로에서 Prometheus는 remote storage에서 레이블 및 시계열 데이터 만 가져옵니다. 데이터에 대한 모든 PromQL의 실행은 여전히 로컬 Prometheus 에서 발생합니다. 즉, 필요한 모든 데이터를 먼저 쿼리하는 Prometheus 서버에 로드 한 다음 처리해야 하므로 remote 읽기 쿼리에는 확장성 제한이 있습니다.
4.1. remote 읽기
Prometheus 저장소 쿼리가 HTTP API 를 통해 로컬 및 원격 저장소로 전송되고 결과가 병합됩니다.
원격 스토리지 사용에 안정성을 유지하기 위해 alert 및 구성 파일 설정은 로컬 스토리지만 사용합니다.

Prometheus 구성 파일(rule.yml)의 remote_read 섹션에서 remote 스토리지 읽기 경로를 구성합니다.
간단하게 원격 저장소에 대한 읽기 endpoint URL과 인증 방법을 지정하기만 하면됩니다. HTTP 기본 또는 토큰 인증을 사용할 수 있습니다.
주요 플래그는 다음과 같습니다.
-- read_recent: true로 설정하면 모든 쿼리가 remote 및 로컬 스토리지에서 응답됩니다. false(기본값)인 경우 로컬 스토리지에서 응답하고 remote로 전송되지 않습니다.
-- required_matchers: (레이블, 값 쌍) 메트릭의 하위 집합만 remote 스토리지를 사용 경우에 사용합니다.
-- remote_timeout: remote 스토리지 요청에 대한 timeout 설정에 사용합니다. (기본값 1m)
이 외에도 인증 및 TLS 구성, 프록시 설정에 대한 옵션도 있습니다.
4.2. remote 쓰기
Prometheus는 스크랩 된 sample을 하나 이상의 remote 스토리지로 전달합니다.
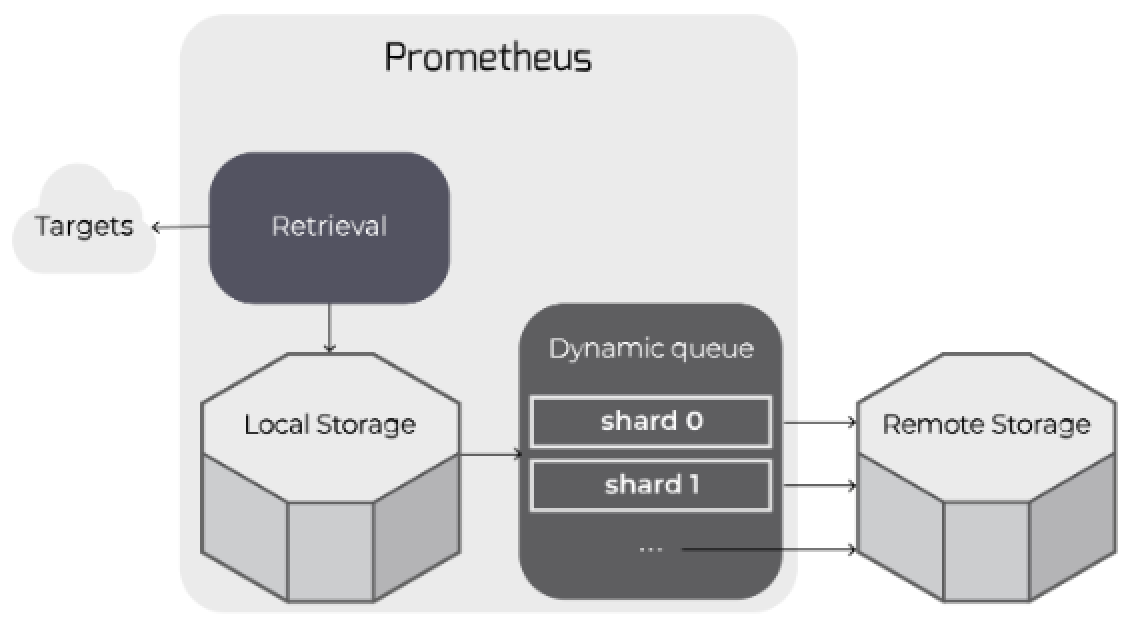
remote 쓰기는 로컬 스토리지에 기록된 시계열 sample을 remote 스토리지에 쓰기 위해 queue에 넣는 방식으로 작동합니다.
dinamic queue는 동적으로 관리되는 shard 세트입니다. 동일한 측정 항목에 대한 시계열 샘플은 특정 샤드에 있게 됩니다.
queue는 들어오는 데이터의 속도를 따라 잡기 위해 remote 스토리지에 쓰는 shard 수를 자동으로 늘리거나 줄입니다.
이를 통해 Prometheus는 최소한의 구성으로 필요한 리소스만 사용하면서 remote 스토리지를 관리 할 수 있습니다.
가끔 느린 remote 요청을 처리하는 동안 처리량을 유지하기 위해 여러 요청을 버퍼링 할 수 있도록 각 샤드에 충분한 용량을 확보하는 것이 좋습니다.
Prometheus 구성 파일의 remote_write 섹션에서 remote 스토리지 쓰기 경로를 구성합니다.
remote_read와 마찬가지로 가장 간단한 구성은 remote 스토리지 쓰기 URL과 인증 방법입니다. HTTP 기본 또는 토큰 인증을 사용할 수 있습니다.
주요 플래그는 다음과 같습니다.
-- remote_timeout: remote 스토리지 요청에 대한 timeout 설정에 사용합니다. (기본값 30s)
-- write_relabel_configs: remote 스토리지에 쓰는 메트릭의 레이블을 변경하거나 제한 할 수 있습니다.
-- queue_config: queue에 대한 일부 제어를 제공합니다. 일반적으로 여기서 변경할 필요가 없으며 Prometheus의 기본값을 사용할 수 있습니다.
이 외에도 인증 및 TLS 구성, 프록시 설정에 대한 옵션도 있습니다.
4.3. remote endpoint 스토리지
Prometheus 의 remote 쓰기 및 읽기 기능을 사용하면 투명하게 sample을 보내고 받을 수 있습니다.
remote 스토리지는 장기 보관을 위한 것입니다. 스토리지 솔루션을 신중하게 평가하여 데이터 볼륨을 처리 할 수 있는지 확인하는 것이 좋습니다.
아래는 remote 스토리지로 사용 가능한 리스트와 속성입니다.
- AppOptics: write
- Azure Data Explorer: read and write
- Azure Event Hubs: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Google BigQuery: read and write
- Google Cloud Spanner: read and write
- Graphite: write
- InfluxDB: read and write
- IRONdb: read and write
- Kafka: write
- M3DB: read and write
- MetricFire: read and write
- New Relic: write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- QuasarDB: read and write
- SignalFx: write
- Splunk: read and write
- TiKV: read and write
- Thanos: read and write
- VictoriaMetrics: write
- Wavefront: write
'ETC DB' 카테고리의 다른 글
| prometheus TSDB format (0) | 2021.07.21 |
|---|---|
| prometheus TSDB 관리 API (0) | 2021.07.21 |
| prometheus 데이터 구조 (2) | 2021.07.21 |
| prometheus 개요 (0) | 2021.07.21 |
| Amazon Aurora DB와 mysql 차이점 (0) | 2021.07.21 |


